- Home
- SQL
- Data Warehouses
- Database Normalization
- Dimensional Modelling
- DWH Appliances
- ETL or ELT
- Training Courses
- Contact Us
Website design by M J Burrow
Copyright © 2010-2011 M J Burrow
Structured Query Language Solutions
Website design by M J Burrow
Copyright © 2010-2011 M J Burrow
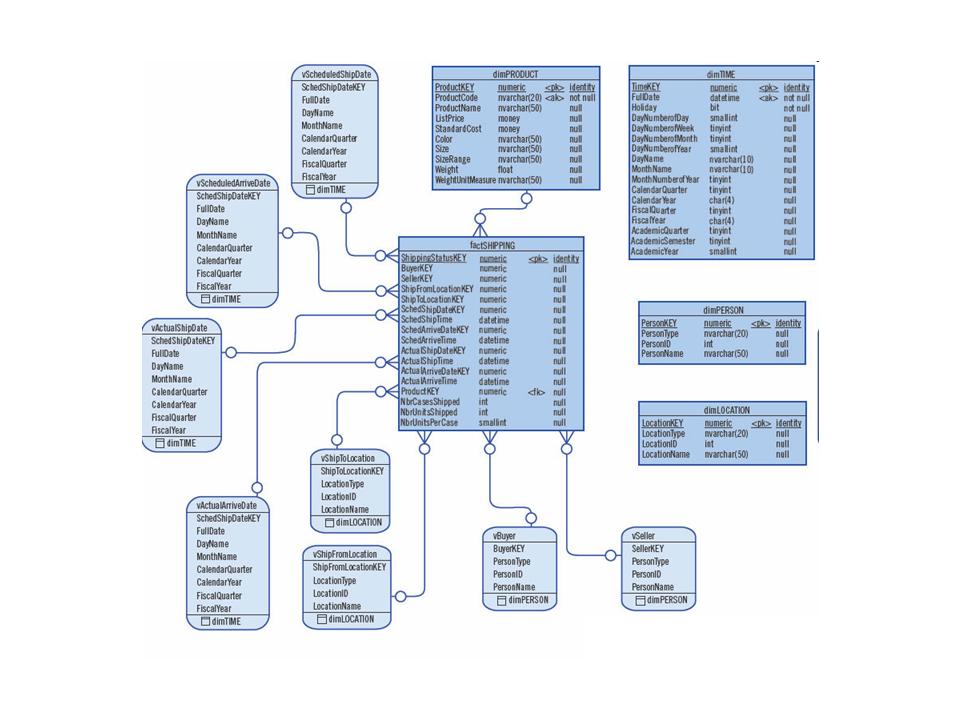
Dimensional modelling is a logical design technique that seeks to present the data in a standard, intuitive framework that allows for high-performance access. It is inherently dimensional, and it adheres to a discipline that uses the relational model with some important restrictions. Every dimensional model is composed of one table with a multipart key, called the fact table, and a set of smaller tables called dimension tables. Each dimension table has a single-part primary key that corresponds exactly to one of the components of the multipart key in the fact table.
A fact table might contain either detail level facts or facts that have been aggregated (fact tables that contain aggregated facts are often instead called summary tables). It is also possible to have a fact table that contains no measures or facts. These tables are called "factless fact tables".
A fact table, because it has a multipart primary key made up of two or more foreign keys, always expresses a many-to-many relationship. The most useful fact tables also contain one or more numerical measures, or "facts," that occur for the combination of keys that define each record. The most useful facts in a fact table are numeric and additive. Being additive is crucial because data warehouse applications almost never retrieve a single fact table record; rather, they fetch back hundreds, thousands, or even millions of these records at a time, and the only useful thing to do with so many records is to aggregate them.
There are three types of measures:
Additive: Measures that can be added across all dimensions.
Non Additive: Measures that cannot be added across all dimensions.
Semi Additive: Measures that can be added across some dimensions and not with others.
Dimension tables, by contrast, most often contain descriptive textual information. Dimension attributes are used as the source of most of the interesting constraints in data warehouse queries, and they are virtually always the source of the row headers in the SQL answer set.
There are four types of dimension:
Conformed Dimension: Dimensions are conformed when they are either exactly the same (including keys) or one is a perfect subset of the other. Most important, the row headers produced in the answer sets from two different conformed dimensions must be able to match perfectly. Conformed dimensions are either identical or strict mathematical subsets of the most granular, detailed dimension. Dimension tables are not conformed if the attributes are labelled differently or contain different values. Conformed dimensions come in several different flavours. At the most basic level, conformed dimensions mean the exact same thing with every possible fact table to which they are joined. The date dimension table connected to the sales facts is identical to the date dimension connected to the inventory facts.
Junk Dimension: A junk dimension is a convenient grouping of typically low-cardinality flags and indicators. By creating an abstract dimension, these flags and indicators are removed from the fact table while placing them into a useful dimensional framework.
Degenerated Dimension: A dimension key, such as a transaction number, invoice number, ticket number, or bill-of-lading number, that has no attributes and hence does not join to an actual dimension table. Degenerate dimensions are very common when the grain of a fact table represents a single transaction item or line item because the degenerate dimension represents the unique identifier of the parent. Degenerate dimensions often play an integral role in the fact table's primary key.
Role-Playing Dimensions: Dimensions are often recycled for multiple applications within the same database. For instance, a "Date" dimension can be used for "Date of Sale", as well as "Date of Delivery", or "Date of Hire". This is often referred to as a "role-playing dimension".
The key advantage of the dimensional design is that it is highly recognizable to the end users and straightforward for non-SQL experts to interrogate.
